Introduction
Working on data pipelines is a very essential part of data engineering. One of the key factors of a well-written pipeline is the ‘Orchestration’, which helps automate most of the schedule and dependencies between tasks thus saving a lot of development time. Apache Airflow is one such orchestration tool that has lot of features and 3rd party integrations which makes it very popular among data engineers to manage workflows.
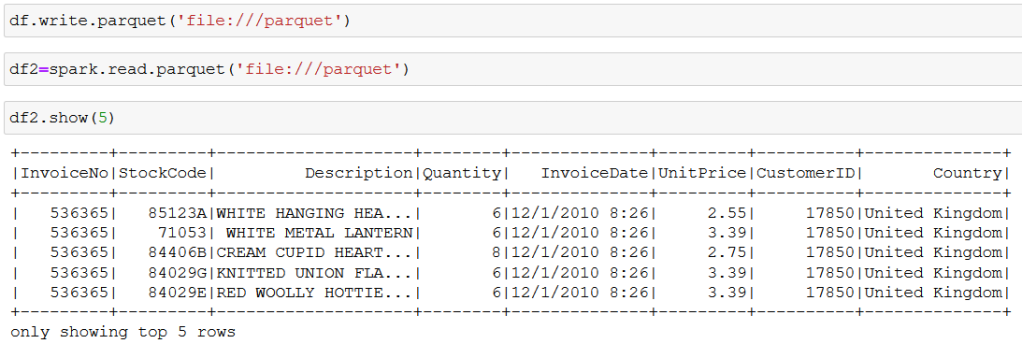
In this blog (first post of the series), I will share how to install, configure, run and visualize a simple pipeline. So, let’s get started. I have used Postgres as Airflow DB (other options are mysql & sqlite)
1. Installing Apache Airflow
mkdir airflow
cd airflow
export AIRFLOW_HOME=/absolute/path/to/airflow/directory
python -m venv venv
. venv/bin/activate
pip install apache-airflow
# optional -- when using Postgres as Airflow metadata DB
pip install psycopg2-binary
2. Setting Postgres to hold Airflow metadata (default is sqlite)
/* Execute below commands in your Postgres server */
CREATE DATABASE airflow_db;
CREATE USER <airflow-db-user> WITH PASSWORD <airflow-db-pass>;
GRANT ALL PRIVILEGES ON DATABASE airflow_db TO airflow_user;
3. Configure Airflow to use Postgres as its metadata database
# Edit "airflow.cfg" file
# Replace with your values and update the value of 'sql_alchemy_conn' to
postgresql+psycopg2://<airflow-db-user>:<airflow-db-password>@<db-host>/airflow_db
# Save "airflow.cfg"
# verify DB connection from Airflow
airflow db check
# Initialize the DB
airflow db init
The “db init” command will ensure that Airflow has access to create required tables (It created 28 tables in my Postgres DB)
4. Create a user to access Airflow webserver
airflow users create \
--username admin \
--firstname Preetdeep \
--lastname Kumar \
--role Admin \
--email no-reply@techwithcloud.com
5. Start Airflow
# start webserver
airflow webserver
# start scheduler
airflow scheduler
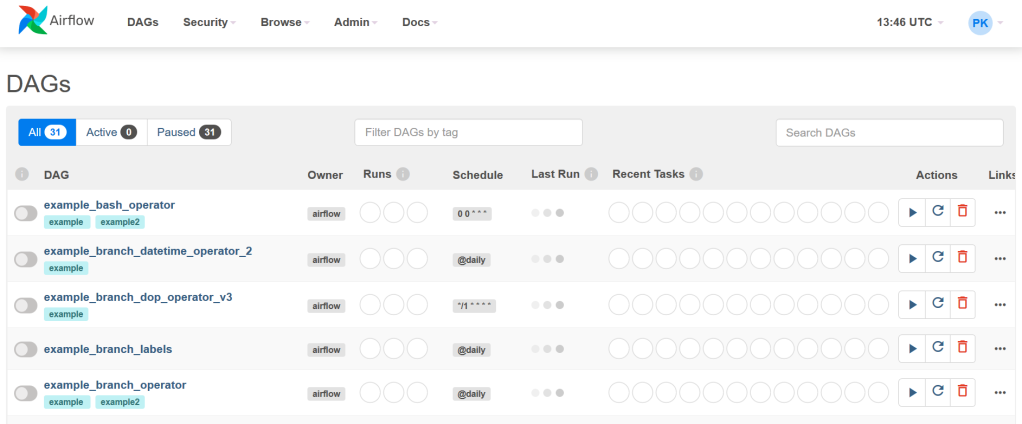
Now, login to http://localhost:8080 and you should see a page similar to the following. There are some default DAGs defined to play around with. DAG (Directed Acyclic Graph) is a set of tasks (vertices) and their dependencies (edges) in such a way that it doesn’t create a cycle or loop among themselves. In other words, it represents a pipeline (I will use DAG and Pipeline interchangeably).
Now that the basic Airflow setup is complete, time to build a pipeline (DAG). Airflow requires DAGs to be created around “Executors”. The default executor is “SequentialExecutor” which can only run one task instance at a time. For this tutorial, I will be LocalExecutor but for production “CeleryExecutor” is highly recommended.
There are two types of executor – those that run tasks locally (inside the
Airflow Docsschedulerprocess), and those that run their tasks remotely (usually via a pool of workers)
6. Using LocalExecutor
Edit "airflow.cfg" file
Change the value of executor to LocalExecutor
Save "airflow.cfg"
# run this command to confirm the change
airflow config get-value core executor
7. Testing with a demo DAG
Now that the Airflow environment is configured, let’s execute a simple DAG
from airflow.operators.python import PythonOperator
from airflow import DAG
from datetime import datetime
default_dag_args = {
'owner': 'techwithcloud',
'depends_on_past': False,
'start_date': datetime(2021, 8, 19),
'schedule_interval':None
}
# Step 1 = Define tasks
def task_1():
print('Hi, I am Task1')
def task_2():
print('Hi, I am Task2')
# Step 2 = Define a DAG
with DAG(
dag_id='simple_dag_demo',
default_args=default_dag_args,
tags=['on demand']
) as dag:
# Define an operator (encapsulate your tasks)
t1 = PythonOperator(
task_id='task_one',
python_callable=task_1
)
t2 = PythonOperator(
task_id='task_two',
python_callable=task_2
)
# define lineage
t1 >> t2
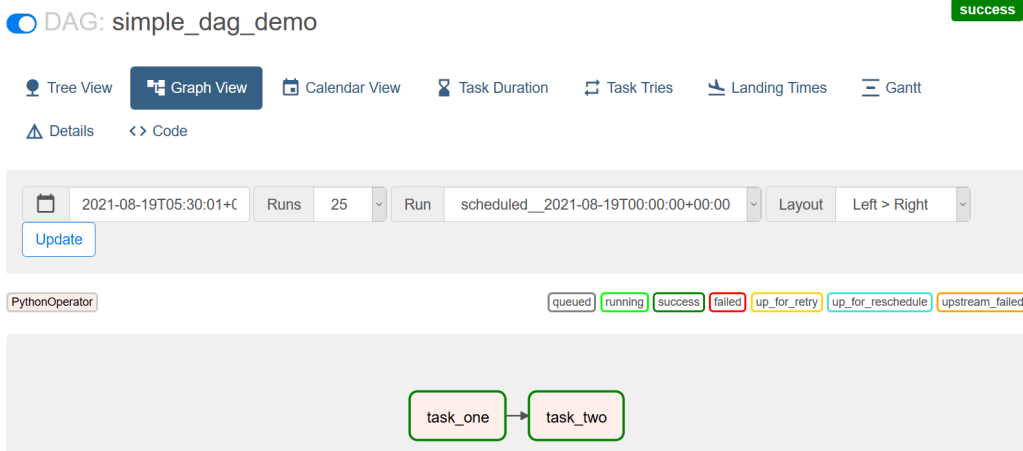
Save this code as demo_dag.py and copy this file to $AIRFLOW_HOME/dags/ folder. Within few minutes, the Airflow scheduler should detect this new DAG. Refresh your Airflow UI, search for this DAG, activate it and you should see something similar as shown below.

To view specific details of a DAG, click on the dag name. I personally find “Graph View” very interesting. From here, you can click on individual tasks and check the logs as well which is very useful in debugging.
8. Passing data across tasks
Airflow provides this feature through XCom (short for cross-communication). Marc Lamberti has written a nice blog dedicated to XCom which I highly recommend. The caveat with this approach is that this information should be a small piece of data (key/value pair) under a certain size limit.
Do not pass sensitive or huge data using XCom
In the following example (an updated version of the above one), I am using two ways of passing value from one task to another. The first one is using a key and the second one is through the “return” keyword.
def task_1():
ti = get_current_context()['task_instance']
# push value associated with a key
ti.xcom_push(key='t1_key', value='t1_xcom_value')
print('Hi, I am Task1')
# push value associated with default key
return 't1_return_value'
def task_2():
ti = get_current_context()['task_instance']
# read a value using key and task_id
xcom_value = ti.xcom_pull(key='t1_key', task_ids=['task_one'])
# read the returned value of a task
return_value = ti.xcom_pull(task_ids=['task_one'])
print('Hi, I am Task2')
print('Explicit Value {} and Default Value {}'.format(xcom_value, return_value));
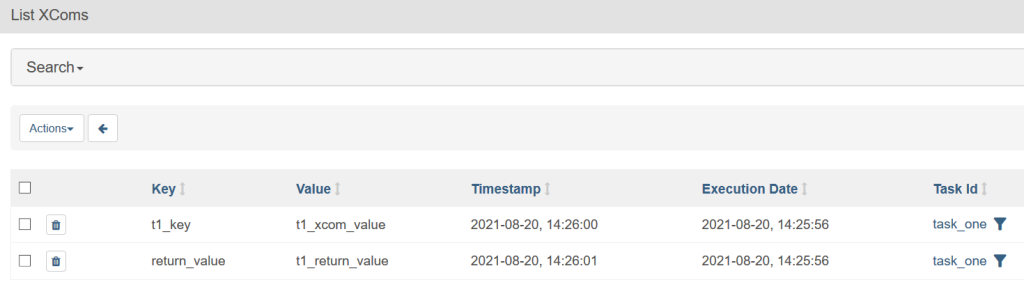
Executing this DAG and observing logs for task_2 gives us the following information

To view all such XCom key/value pairs from all DAGs, navigate to Admin -> XComs
9. Task Retries and Error Handling
Airflow provides additional benefits of retrying a task if it has failed during a run. This is super useful when a task has to make HTTP calls or DB connections but should also handle occasional loss of connectivity, busy server, or Throttling.
# add retry options to default arguments passed to DAG object
default_dag_args = {
'owner': 'techwithcloud',
'depends_on_past': False,
'start_date': datetime(2021, 8, 20),
'schedule_interval':timedelta(seconds=15),
'retries': 3,
'retry_delay': timedelta(seconds=3),
'retry_exponential_backoff': True
}
# raise exception for Airflow to retry
def task_1():
ti = get_current_context()['task_instance']
print('Hi I am task1 from demo dag', ti.try_number)
# raise an exception which will trigger retry
if randint(1, 100) < 50:
raise AirflowException("Error message")
Executing this new example forces Airflow to retry up to 3 times. You can see the retry attempts in UI by clicking on “Log” in the DAGs details section.

Conclusion
In this post, I shared how to get started with Airflow in a standalone mode. In the next part, I will share how to run a sample ETL pipeline using S3 and Postgres operators.